




Executive summary
What are common application recovery challenges?
Major organizations face a number of common application recovery challenges, including complex architectures, the increasing volume of data they have to manage, and outdated disaster recovery processes.
Application recovery in today's complex IT landscapes presents a multitude of challenges. Modern applications are often distributed, interconnected, and reliant on a variety of underlying infrastructure components, making it difficult to orchestrate a swift and effective recovery. One of the primary hurdles is the sheer volume of data and dependencies that must be accounted for across these systems. Ensuring data consistency and integrity across disparate systems during a recovery process is a significant undertaking.
Furthermore, traditional (or legacy) recovery methods rely on manual processes, which are prone to human error and can lead to prolonged downtime. The lack of standardized procedures and automated workflows can result in inconsistent recovery outcomes and increased recovery times. In addition, the ever-increasing threat of cyber attacks, like ransomware, adds a layer of complexity to recovery, as backups can be compromised, and recovery procedures must be secure.
An introduction to Cutover Recover: Next-generation architecture
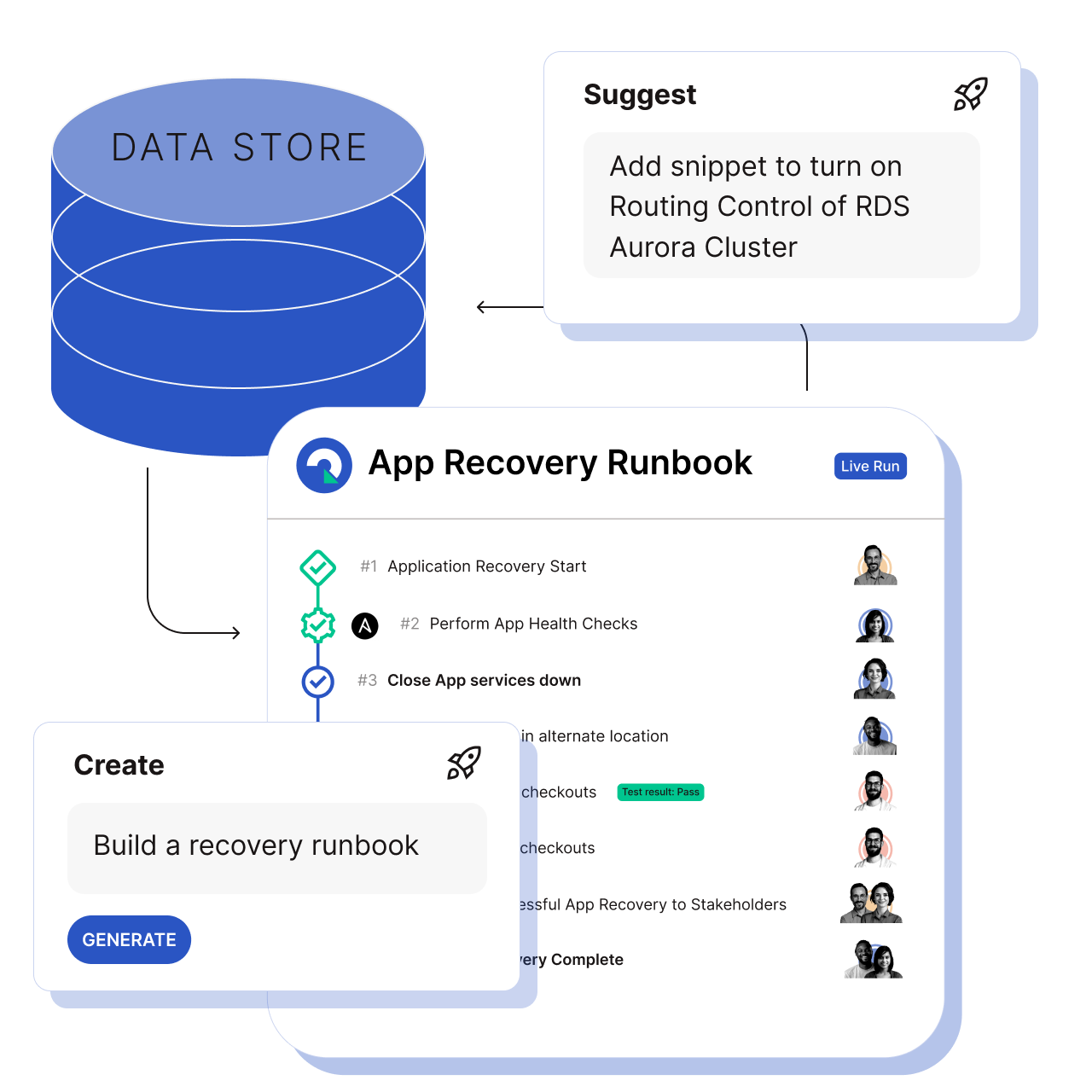
Cutover Recover is designed to address the complexities of modern application recovery by providing a prescriptive, automated, and intelligent approach. It moves beyond traditional, reactive recovery methods by offering a proactive and standardized architecture that significantly reduces recovery time and minimizes data loss. At its core, Cutover Recover leverages the comprehensive Application Metastore that integrates design-time and run-time data, enabling the automated generation of recovery plan templates. This, combined with pre-defined runbook templates for common application patterns in cloud and on-premises application architectures ensures consistency and efficiency across recovery scenarios.
The Cutover Recover next-generation architecture benefits are manifold. By automating recovery processes and standardizing runbooks, organizations can significantly reduce the risk of human error and accelerate recovery times.
Furthermore, the integration of AI-enabled runbooks allows for continuous optimization and adaptation, ensuring that recovery processes remain effective in dynamic environments. Ultimately, Cutover Recover empowers organizations to achieve faster time to value, enhance application resilience, and minimize the business impact of disruptions.
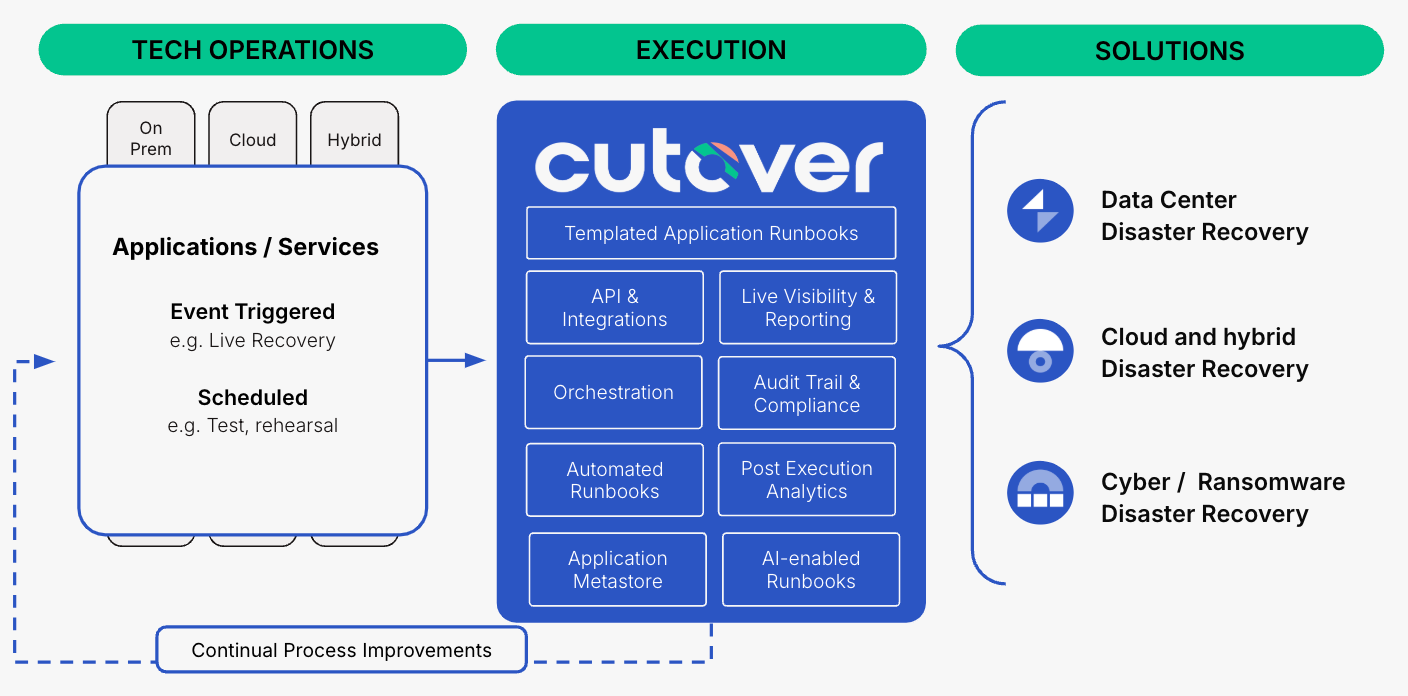
Cutover Recover highlights
Cutover Recover’s architecture distinguishes itself through a powerful combination of automation, intelligence, and standardization, fundamentally transforming application recovery. A key highlight is its Application Metastore, which acts as a central repository for both design-time and run-time application data, enabling the automated creation and maintenance of precise recovery plans. This eliminates the reliance on outdated, manual documentation and ensures recovery procedures are always up to date. Further enhancing efficiency are pre-defined runbook templates, meticulously crafted for common application and failover patterns, drastically reducing the time required to execute recovery actions.
Moreover, the integrated artificial intelligence functionality with Cutover AI elevates Cutover Recover by optimizing recovery patterns and processes through built-in algorithms based solely on the customer’s data. This AI-driven approach allows for dynamic adjustments and continuous improvement, ensuring that recovery procedures are not only fast but also highly adaptive to evolving environments.
Finally, Cutover Recover provides a clear Recovery Time Objective (RTO)/recovery time actual (RTA) calculated comparison, enabling organizations to quantify recovery effectiveness and identify areas for improvement. These functional attributes collectively make this Cutover Recover next-generation architecture a robust and intelligent solution for ensuring rapid and reliable application resilience.
Introduction: The need for rapid application recovery
The escalating complexity of today's application environments, characterized by distributed architectures and intricate dependencies, has amplified the business impact of prolonged downtime and data loss, making rapid application recovery a critical imperative. Traditional recovery approaches, often hampered by manual processes and limited automation, struggle to meet the demands of this dynamic landscape, highlighting the urgent need for solutions that prioritize "time to value" in recovery.
The increasing complexity of modern application environments
Modern application environments are characterized by a confluence of factors that contribute to their increasing complexity. The shift towards microservices architectures, containerization, and cloud-native technologies has resulted in highly distributed systems, where applications are composed of numerous interconnected components. This distribution, while offering scalability and flexibility, introduces intricate dependencies and interrelationships that must be carefully managed. The proliferation of diverse technologies, including multiple databases, middleware, and APIs, further complicates the landscape, requiring specialized expertise and tools for effective management and recovery.
Furthermore, the adoption of hybrid and multi-cloud strategies adds another layer of complexity. Applications may span multiple cloud providers and on-premises infrastructure, creating a heterogeneous environment that demands seamless integration and orchestration. This complexity makes it increasingly difficult to maintain a comprehensive understanding of application dependencies and to ensure consistent recovery across diverse platforms. The dynamic nature of these environments, with frequent deployments and updates, necessitates agile and automated recovery solutions that can adapt to changing conditions.
What is the business impact of prolonged downtime and data loss?
Top impacts include lost revenue, damaged reputation, and eroded customer trust.
Prolonged downtime and data loss can have devastating consequences for businesses, impacting revenue, reputation, and customer trust. In today's interconnected world, even brief outages can lead to significant financial losses, as online transactions are disrupted, and critical services become unavailable. For businesses reliant on e-commerce or digital platforms, downtime directly translates to lost sales and revenue. Beyond the immediate financial impact, extended outages can erode customer confidence and damage brand reputation, as customers may seek alternative providers they perceive as more reliable.
Moreover, data loss can have far-reaching legal and regulatory implications, particularly in industries subject to strict data privacy and compliance requirements. The loss of sensitive customer data can result in hefty fines and penalties, as well as costly litigation. The inability to recover critical business data can also impede operational efficiency and hinder decision-making, leading to long-term competitive disadvantages. In essence, prolonged downtime and data loss pose a significant threat to business continuity and can have lasting repercussions on an organization's bottom line and overall viability.
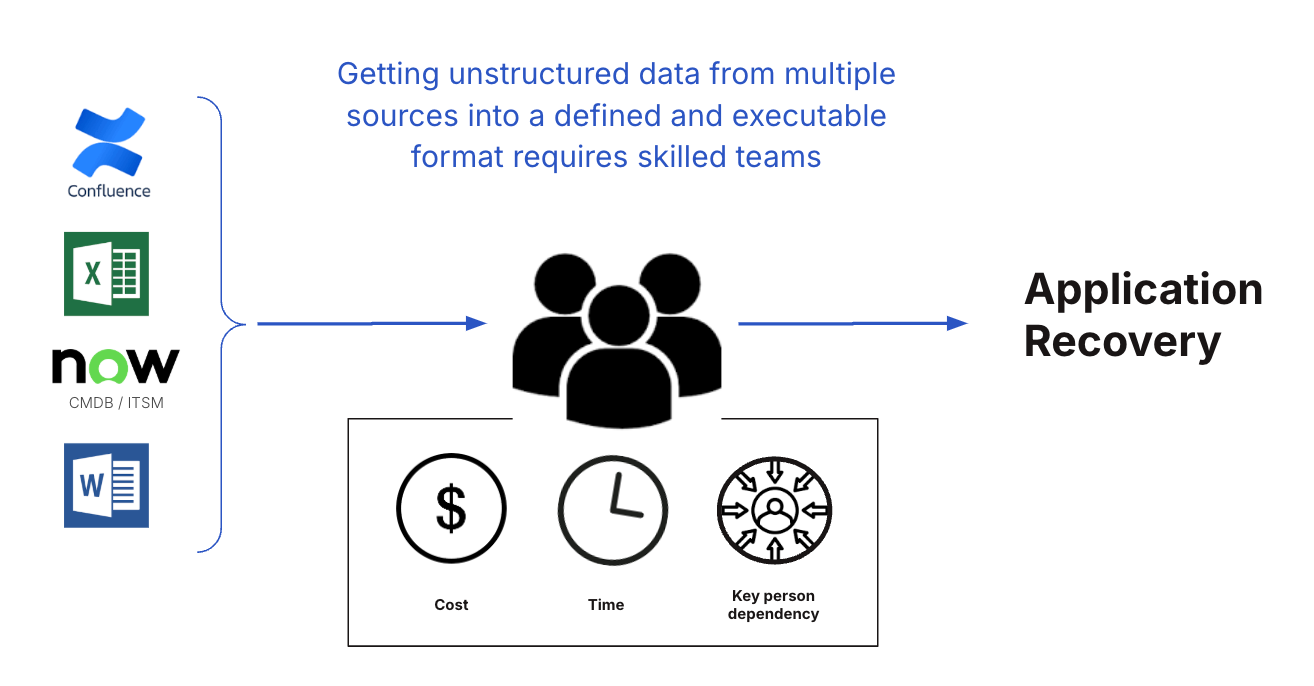
What are the limitations of traditional recovery approaches?
Traditional recovery approaches often rely heavily on manual processes, outdated documentation, and fragmented tools, leading to significant limitations in today's fast-paced digital landscape. Manual recovery procedures are inherently prone to human error, which can prolong downtime and introduce inconsistencies. The reliance on static, often outdated, single-threaded runbooks and recovery plans means they frequently fail to reflect the dynamic nature of modern application environments, leading to unexpected complications during recovery. Moreover, traditional methods lack the ability to effectively orchestrate recovery across distributed, cloud-native architectures, resulting in slow and unpredictable recovery times.
Another significant limitation is the lack of comprehensive visibility into application dependencies and interrelationships. Traditional tools often provide siloed views of infrastructure and applications, making it difficult to identify and address critical dependencies during recovery. This lack of holistic visibility can lead to incomplete recoveries and cascading failures. Additionally, traditional approaches often struggle to integrate with modern DevOps practices, hindering the ability to automate and streamline recovery processes. The result is a reactive, rather than proactive, approach to recovery, where organizations are constantly playing catch-up, rather than anticipating and mitigating potential disruptions.
"Time to value" in recovery
In the context of application recovery, "time to value" transcends simply restoring functionality; it emphasizes the speed and efficiency with which an organization can return to full operational capacity and resume delivering value to its customers. It shifts the focus from merely achieving recovery to minimizing the duration of disruption and maximizing the return on recovery investments. This concept acknowledges that every moment of downtime translates to lost revenue, diminished customer trust, and potential reputational damage. Therefore, the goal is not just to recover, but to recover rapidly and effectively, restoring critical services and data with minimal delay.
"Time to value" also underscores the importance of proactive recovery strategies that prioritize automation, standardization, and intelligence. By streamlining recovery processes and leveraging AI-driven insights, organizations can significantly reduce the time required to restore critical applications and data, accelerating the resumption of business operations. This approach not only minimizes the immediate impact of disruptions but also enhances long-term resilience by fostering a culture of rapid recovery and continuous improvement. In essence, "time to value" in recovery is about maximizing the speed and efficiency of restoration to minimize business disruption and rapidly return to delivering value
Cutover Recover: A prescriptive approach
Cutover Recover champions a prescriptive approach, moving beyond reactive recovery tactics to offer a structured, proactive methodology. It provides a defined pathway for application recovery, ensuring consistency and predictability in even the most complex environments. This architecture integrates key components like a Prescriptive Target Operating Model, pre-defined runbook templates, the Cutover Application Metastore, and AI-enabled runbooks, all working in concert. By standardizing processes and automating critical steps, Cutover Recover eliminates ambiguity and reduces the potential for human error, leading to significantly faster recovery times and a more resilient IT infrastructure. This prescriptive nature allows organizations to build a repeatable, reliable recovery strategy, minimizing the impact of disruptions and maximizing operational uptime.
Overview of the Cutover Recover methodology
The Cutover Recover architecture methodology is designed to streamline and accelerate application recovery through a structured, automated, and intelligent approach.
It begins with a comprehensive assessment of the application environment, capturing critical design-time and run-time data within the Application Metastore. This centralized repository serves as the foundation for automated recovery plan generation and maintenance. Leveraging pre-defined runbook templates, tailored to common application and failover patterns, the methodology ensures the consistent and efficient execution of recovery procedures. Furthermore, the integration of AI agent tasks embedded in runbooks allows for continuous optimization and adaptation, enabling the framework to dynamically respond to evolving conditions. By focusing on standardization, automation, and intelligent insights, the Cutover Recover methodology empowers organizations to achieve rapid and reliable application resilience, minimizing downtime and maximizing business continuity.
Key components of the Cutover Recover next-generation architecture:
The Cutover Recover framework is composed of several key components, each designed to work synergistically to provide a robust and efficient application recovery solution.
Prescriptive target operating model
The cornerstone of Cutover Recover is its Prescriptive Target Operating Model, which provides a standardized blueprint for application recovery. This model defines the optimal state for recovery processes, outlining clear procedures, roles, and responsibilities. By establishing a consistent framework, organizations can eliminate ambiguity and ensure that recovery efforts are executed with precision and efficiency. The Prescriptive Target Operating Model promotes uniformity across diverse application environments, reducing the variability that often leads to errors and delays. It also guides the development of automated runbooks and the configuration of the Application Metastore, ensuring that all components of the framework align with the defined recovery objectives. This standardized approach dramatically improves the reliability and speed of application recovery, minimizing the impact of disruptions and accelerating the return to normal operations.
Pre-defined runbook templates
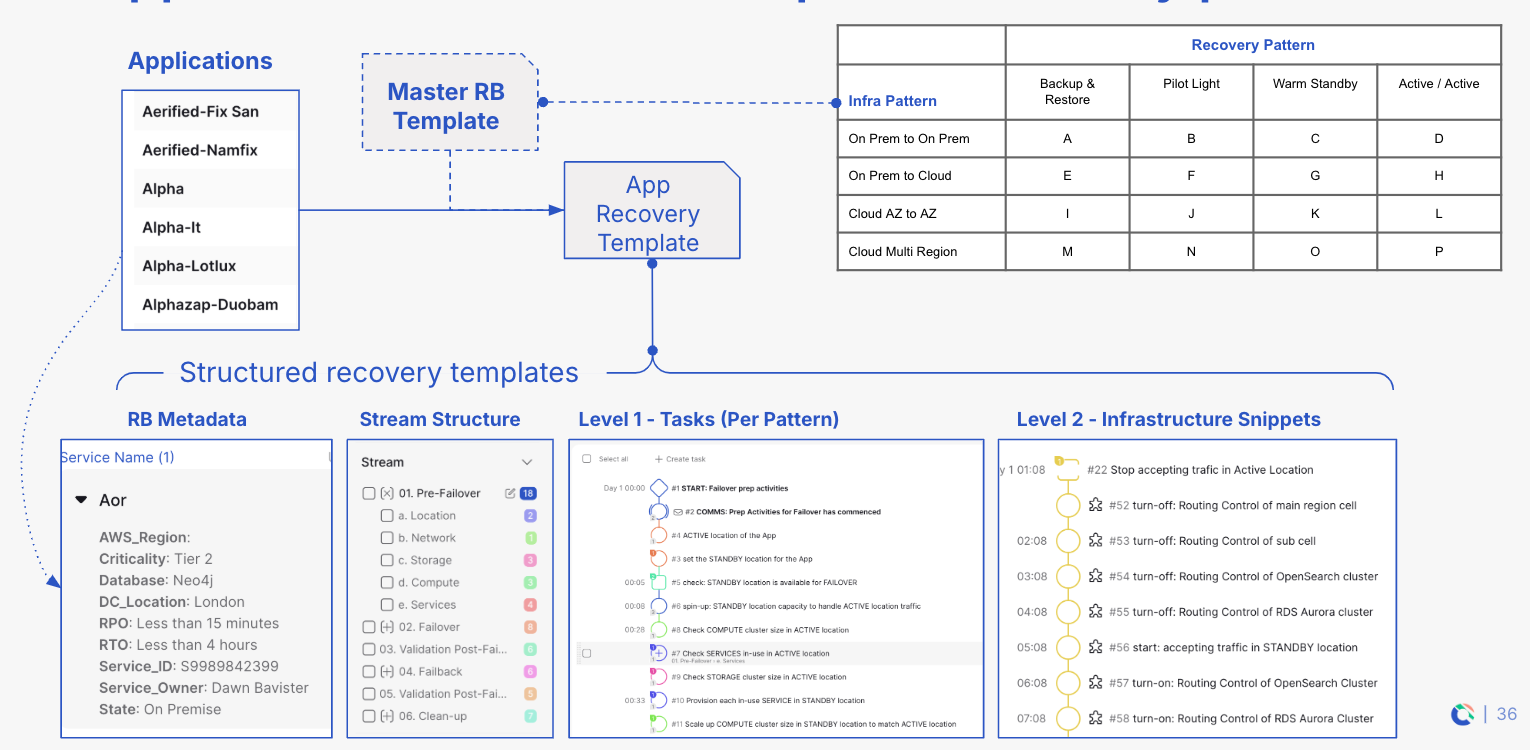
Pre-defined runbook templates within Cutover Recover serve as a critical component for streamlining and standardizing recovery execution. These templates are designed to address common application and failover patterns, providing a structured and repeatable approach to recovery. By encapsulating best practices and proven procedures, these templates eliminate the need for ad-hoc, error-prone manual interventions. They offer a ready-to-use foundation, allowing organizations to quickly adapt and customize them to their specific application requirements. This not only accelerates recovery times but also ensures consistency across diverse recovery scenarios. The templates are designed to be modular and extensible, enabling organizations to easily incorporate them into their existing workflows and integrate them with the Application Metastore and AI-enabled runbooks, ensuring a cohesive and efficient recovery process.
Application Metastore
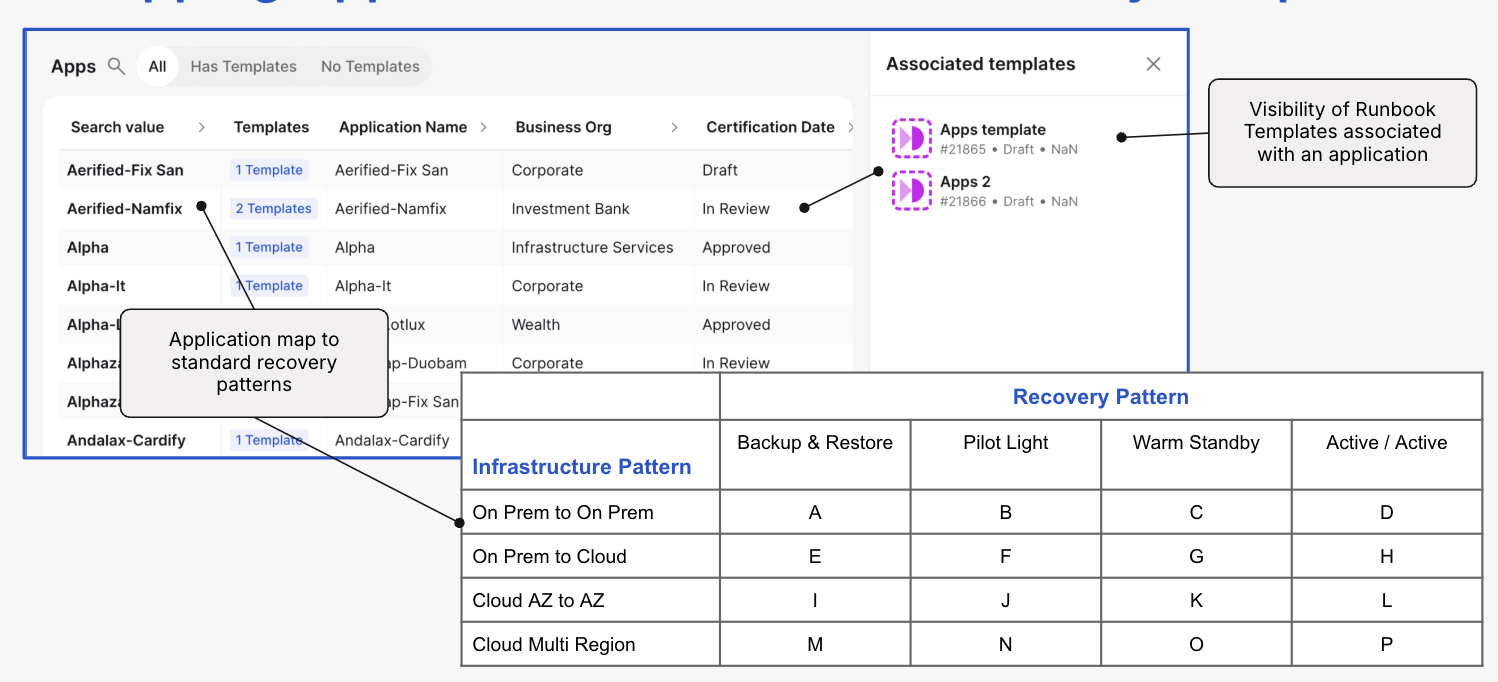
The Application Metastore is an integral part of Cutover Recover’s next-gen architecture, providing a unified repository for both design-time configuration management database (CMDB) and run-time (monitoring) application data. This comprehensive data consolidation is crucial for automating and optimizing the recovery process. By housing detailed information about application dependencies, configurations, and performance metrics, the Application Metastore enables the automated generation and maintenance of accurate and always up-to-date recovery plans. It eliminates the reliance on fragmented, outdated documentation, ensuring that recovery procedures reflect the current state of the application environment. Furthermore, this centralized data source facilitates seamless integration with other components of the architecture, such as pre-defined runbook templates and AI-enabled runbooks, ensuring a cohesive and intelligent approach to application recovery. The Application Metastore thus serves as the foundation for proactive and efficient restoration, minimizing downtime and enhancing overall resilience.
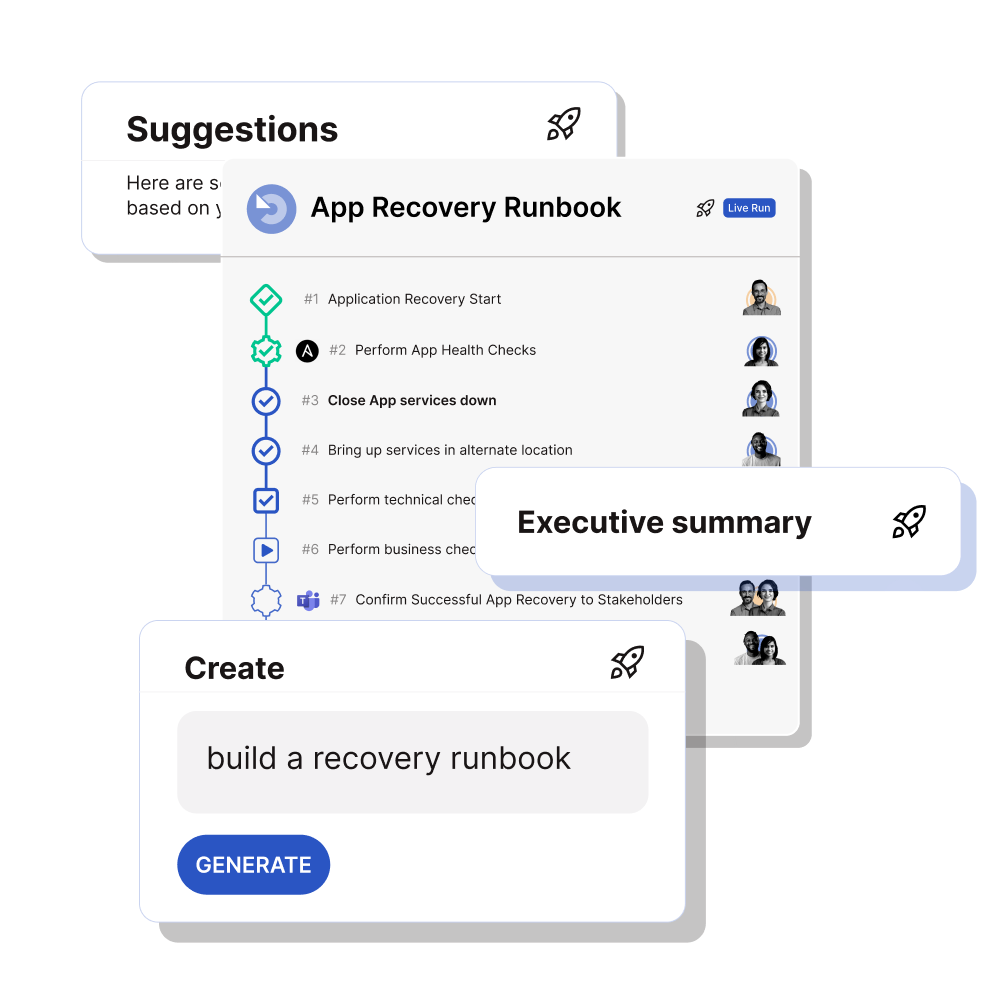
Cutover AI
Cutover AI-enabled runbooks represent a significant leap forward in application recovery, leveraging artificial intelligence to optimize and enhance the recovery process within Cutover Recover. By integrating intelligent algorithms based on the customer‘s data, Cutover AI can analyze runbooks and instantly create summaries for them. Additionally, Cutover AI identifies patterns to suggest improvements based on predicted potential issues, thereby enabling proactive adjustments and improvements to the runbook recovery procedures. Cutover AI can also create runbooks based on structured or unstructured data which saves time and money.
Finally, Cutover enables an AI-agent approach that goes well beyond static, pre-defined steps, allowing for dynamic adaptation to changing conditions and real-time insights with human oversight. Cutover AI agents empower the runbooks to learn from each recovery event, continuously refining their execution and minimizing human error. Cutover AI agents emphasize transparency and control, and align with the following principles:
- Explainability: Being able to see the data shared with the agent, how it thought about it and what it suggested. This is fundamental to Cutover runbooks that document the data used by the Cutover AI agent, its reasoning, and the actions it recommended, providing a clear audit trail.
- Transparency: Cutover provides an immutable audit log of data that is critical to understand and track the incident response process, including the Cutover AI agent’s suggested actions, which team member approved them, and how the AI agent amended the directed graph of tasks in the action space.
- Safety: All AI agents’ actions and rights need to be expected and controlled. The Cutover AI agent can only act with the rights and authority to do certain things based on approvals from people. In Cutover runbooks, team members can add their authority to AI agent tasks so it will not act in an uncontrolled way that might cause problems elsewhere, for example, in the infrastructure domain. In Cutover, the AI agent's permissions and roles are defined and enforced, ensuring that it operates within preset boundaries.

RTO/RTA comparison calculation
Cutover's RTO/RTA Comparison Calculation provides a critical metric for measuring the effectiveness of application recovery efforts. Recovery Time Objective (RTO) represents the target time within which an application or system must be restored after a disruption, while Recovery Time Actual (RTA) is the actual time taken to complete the recovery. By comparing these two metrics, organizations can gain valuable insights into their recovery performance. The methodology involves meticulously tracking the time taken for each stage of the recovery process, from incident detection to full restoration. This data is then used to calculate the RTA, which is subsequently compared to the pre-defined RTO. Any discrepancies between the two highlight areas where recovery processes may be inefficient or require improvement.
This RTO/RTA analysis serves as a powerful tool for identifying bottlenecks and optimizing recovery procedures.
By pinpointing areas where the RTA exceeds the RTO, organizations can focus their efforts on streamlining processes, automating tasks, and improving resource allocation. For example, if the analysis reveals that manual data restoration is consistently delaying recovery, organizations can explore automated backup and restore solutions. Furthermore, the RTO/RTA comparison allows for the quantification of the benefits of Cutover Recover. By demonstrating a consistent reduction in RTA and alignment with RTO targets, organizations can demonstrate the tangible value of the framework in minimizing downtime and enhancing resilience. This data-driven approach provides a clear and objective measure of recovery effectiveness, enabling organizations to continuously improve their recovery capabilities.
Cutover Recover implementation and deployment: A phased approach
Cutover's implementation and deployment follows a phased approach, ensuring a smooth and effective transition to the Cutover Recover next-generation architecture. Implementation begins with a thorough assessment of the organization's existing application environment, identifying critical dependencies and recovery requirements. This assessment informs the configuration of the Application Metastore and the customization of pre-defined runbook templates. Step-by-step guidance and required integrations are provided throughout the process, covering everything from initial setup to ongoing maintenance. Integration with existing IT infrastructure and tools, such as CMDBs, asset performance management (APM) solutions, and automation platforms, is prioritized to minimize disruption and maximize compatibility.
To mitigate risk and ensure success, pilot programs and phased rollouts are recommended. Starting with a pilot deployment for a select group of applications allows organizations to validate Cutover Recover’s effectiveness and identify any potential issues before broader implementation. This phased approach enables iterative improvements and refinements, ensuring that the framework aligns with the organization's specific needs. Crucially, comprehensive training and knowledge transfer are provided to empower recovery teams with the skills and expertise required to effectively utilize the Cutover Recover framework. This includes hands-on training on runbook execution, AI-driven optimization, and Application Metastore management, ensuring that teams are fully equipped to handle recovery scenarios.
Case study: Global Financial Institution enhances IT disaster recovery with Cutover Recover
A leading global Financial Institution, facing increasing regulatory scrutiny and the rising threat of cyber attacks, sought to modernize its IT disaster recovery (DR) strategy. Traditionally reliant on manual processes and fragmented documentation, the organization struggled to meet stringent RTO/recovery point objective (RPO) requirements. They implemented Cutover Recover to automate and standardize their DR procedures, leveraging the Application Metastore to centralize critical application data and utilizing pre-defined runbook templates for common failover scenarios.
The results were significant. By automating 80% of their DR processes, the institution reduced their average RTA by 60%, consistently meeting their RTO targets. The AI-enabled runbooks further optimized resource allocation during failovers, leading to a 30% reduction in recovery costs. "Cutover Recover transformed our DR capabilities," stated the Head of IT Resilience. "The platform's automation and intelligence have not only accelerated our recovery times but also provided us with the confidence to navigate complex disruptions. The centralized Metastore has eliminated inconsistencies and given us a single source of truth for all recovery procedures.
We now have a much more predictable and reliable recovery process." Feedback from the DR teams highlighted the ease of use of the platform and the significant reduction in manual effort. The ability to track and analyze RTO/RTA metrics provided valuable insights for continuous improvement, leading to a more robust and resilient IT infrastructure.
Conclusion: Cutover Recover transforms application resilience
Cutover Recover next-generation architecture is fundamentally transforming application resilience by providing a prescriptive, automated, and intelligent approach to recovery. The key benefits, including significantly reduced recovery times, minimized human error, and enhanced compliance, are achieved through the framework's core components: The Prescriptive Target Operating Model, pre-defined runbook templates, the Application Metastore, and AI-enabled runbooks. By centralizing application data, standardizing recovery procedures, and leveraging AI for optimization, Cutover empowers organizations to achieve unprecedented levels of resilience.
Looking ahead, the future of application recovery will be increasingly driven by AI and automation. As application environments become more complex and dynamic, the ability to predict and proactively mitigate disruptions will be paramount. Cutover AI, with its machine learning capabilities, will continue to play a pivotal role in optimizing recovery processes and ensuring seamless business continuity. Organizations that embrace these technologies will gain a significant competitive advantage in navigating the challenges of modern IT landscapes.
To experience the transformative power of Cutover Recover, we invite you to take the next step. Contact our team today to schedule a demo and learn how our framework can enhance your organization's application resilience. Let us help you move from reactive recovery to proactive resilience, ensuring your critical applications are always available and performing at their best.

.webp)
