




Today’s financial services (FS) CIOs face immense pressure to manage and operate their organizations like startups—fast and nimble. But unlike a startup, FS organizations are heavily encumbered by a complex, interconnected web of technologies, delivery models, and processes. Any change within this web, from small system updates to new feature rollouts to large-scale migrations, presents risk for an information technology (IT) failure. Recent IT-related incidents have had disastrous outcomes for several institutions and their customers, prompting renewed government scrutiny and demand for different tools and approaches to manage change. This paper discusses why the industry is facing more IT failures and introduces the use of a Collaborative Automation platform to coordinate work across people and technology to eliminate disruptive failures and ensure technology resilience.
Today, FS firms find themselves competing not just against other FS organizations, but against consumers’ evolving expectations for greater levels of reliability, personalization, and service—expectations driven by an onslaught of disruptive technologies and innovative companies. The trend has forced established financial institutions to embrace new technologies, rethink business models, and accelerate the development of new products and services.
Meeting these new challenges, while navigating stricter regulatory requirements, has dramatically changed the FS CIO’s agenda. Traditional responsibilities such as adding new systems and capabilities requested by the business; managing information technology development, operations, and maintenance; and ensuring systems are always ready to support the business are still relevant. However, the explosion of new platforms, apps, devices, data, microservices, and the cloud requires CIOs to now manage a larger, more diverse IT delivery model than ever before. Increased use of outsourcing arrangements, artificial intelligence, and machine learning will further increase complexity to unknown levels. Additionally, the demand for innovative ideas and faster rollouts to meet the increased velocity of marketplace change forces CIOs to operate their teams like startups—fast and nimble.
Unlike true startups, financial institutions have extensive IT infrastructures and legacy systems that run their existing businesses. This environment is highly complex and increasingly interconnected, which means a change, whether it be an improvement rollout, security update, or new system addition, is fraught with risk. For CIOs, maintaining resilience— an organization’s ability to maintain acceptable service levels through, and beyond, severe disruptions to its critical processes and the IT systems which support them—and responding appropriately to incidents has become a considerable challenge.
While many service disruptions are minor and can be quickly rectified, some can have enormous ramifications for the business, including dramatic shifts in customer perception, brand value, financial loss, and, at the extreme, regulatory censure. Of even greater concern is the impact a failure can have on businesses and a country’s economy.
For example, in 2019, a data breach was discovered at Equifax, one of the major credit reporting companies. The breach, which had been in operation since 2017 and was discovered by accident, exposed social security numbers and other sensitive information for roughly half the U.S. population. As restitution, Equifax agreed to pay at least $700 million to settle lawsuits over the breach, including $425 million in monetary relief to consumers, in an agreement with federal and state authorities. In 2020, Equifax was made to pay further settlements relating to the breach: $7.75 million (plus $2 million in legal fees) to financial institutions in the US plus $18.2 million and $19.5 million to the states of Massachusetts and Indiana respectively.
Another tale of failure occurred in April 2018 to TSB. During an attempt to move to a new core banking platform, testing was inadequate and the system failed, resulting in nearly 1.9 million customers being locked out of their accounts for weeks.1 The debacle cost the company £366 million, of which £130 million went toward customer compensation and £25 million paid for an incident report ordered by the Financial Conduct Authority (FCA) and Prudential Regulation Authority.2 The report found TSB’s Spanish parent company Sabadell had “cut corners” with critical IT testing.3 In addition, the incident caused the company to lose an estimated 80,000 customers. TSB was fined a further £29.7 million by the FCA in 2022.
Technology resilience is more important than ever
What each of these disruptions demonstrates, apart from a huge reliance on technology, is that the FS industry struggles to maintain technology resilience and to deal quickly and effectively with operational risk. The FCA found that 234 consumer firms had failures in 2021 and big banks were hit with $1.8 billion in penalties in 2022 with many banks paying over $200 million each to the regulator in fines.
Although new technologies can offer more in terms of security and flexibility, the rate of innovation can also create risk and instability through added complexity and constant change. Our 2022 survey into the state of resilience in the cloud found that 73% of leaders incorrectly assume that to some degree resilience is automatic in the cloud, indicating they are underestimating the level of governance and structure that must be put in place in a cloud resilience strategy. This is confirmed by Uptime Institute’s findings that, since 2016, 63% of all publicly-reported outages were caused by third-party and commercial IT operators such as cloud, hosting, colocation, and telecommunication providers.
The single biggest cause of all IT service downtime was networking-related problems due to increasing complexity
The effects of technology failure are getting worse:
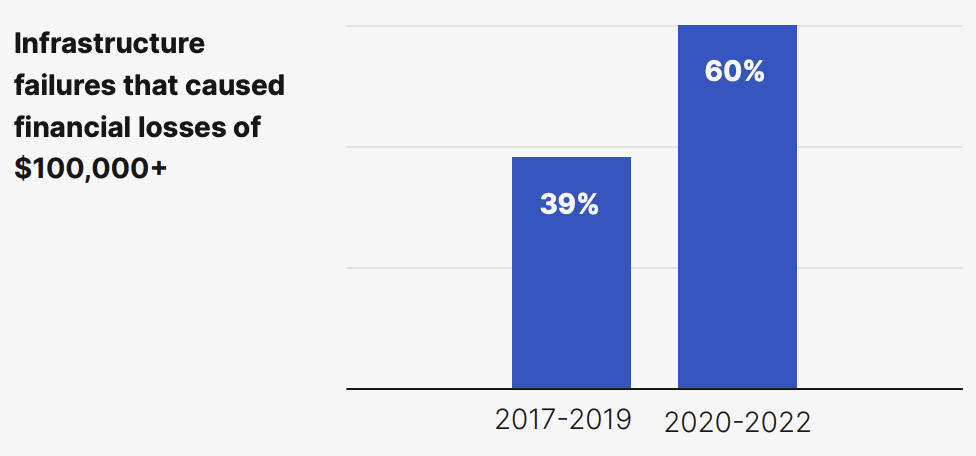
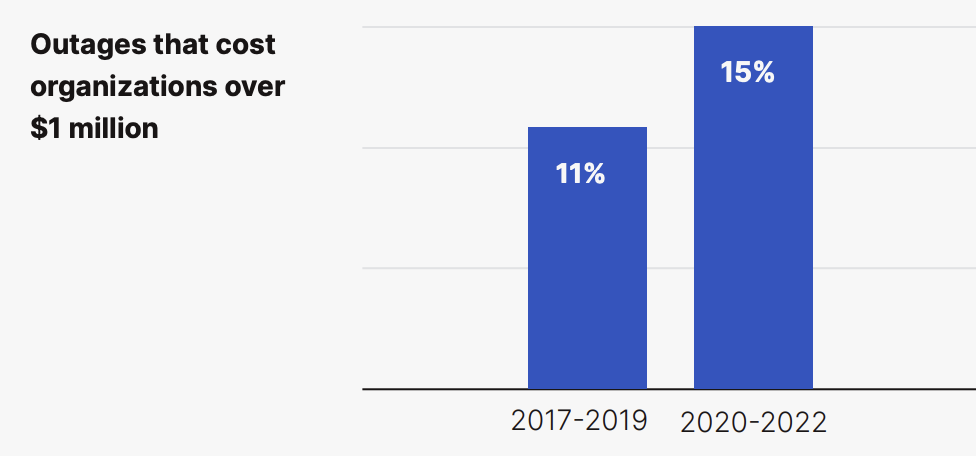
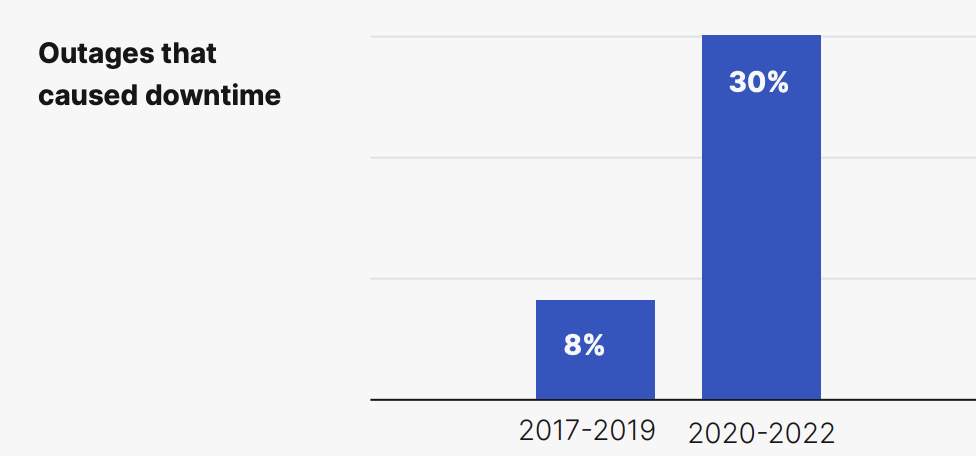
According to the Center for Evidence-Based Management, “‘every time a system is changed and either code released or hardware upgraded there is a risk of making a mistake,’ and that problems can arise when you see ‘aggressive management pushing changes to be released before they are fully tested in order to meet deadlines.’” This implies that investor needs can often push CIOs to accelerate timelines and skip critical steps, which can lead to disastrous outcomes, as in the case of TSB.
The uptick in IT-related incidents within the FS sector and the far-reaching impact on customers and businesses has caused governments worldwide to take notice. In fact, a report by the House of Commons Treasury Committee suggests regulators must give regulating operational risk and resilience as much importance as they do regulating prudential and conduct risks. Furthermore, the report urges that firms, and individuals within firms, be held accountable for their failures.
The House of Commons Treasury Committee suggests regulators must give regulating operational risk and resilience as much importance as they do regulating prudential and conduct risks. In his speech at the 20th Annual Operational Risk Europe conference in London, Bank of England’s Deputy CEO and Executive Director Lyndon Nelson shared, “In my thirty years…resilience is certainly not a new topic nor are all of its challenges unique, but [cyber threats and technological change] have conspired to make it today one of the most important.” 5
Traditional methods of managing risk compromise technology resilience
Unfortunately, most banks have a difficult time understanding, measuring, and managing the interconnected factors that make up resilience, including human behavior, processes, and IT systems. Tools and methods to systematically control risk, for the most part, remained unchanged. Teams still turn to project management software, spreadsheets, emails, and conference calls to manage and orchestrate highly complex critical change events, such as migrating to a new data center or cloud platform. Success using these archaic toolsets relies heavily on the Program or Project Manager’s competence to orchestrate tasks and predict issues well before they turn into problems. This dependence on a “hero” to “save the day” further subjects a project to human error and delays, e.g. progress grinding to a halt if a project manager is unavailable due to illness.
The need for Collaborative Automation to achieve success
Executing change is still heavily dependent on people. Twenty, even ten years ago, most large transformational changes, such as moving to a new data center or upgrading an ATM system, were managed by an internal IT team who, in most cases, worked in the same building. Days in a conference room hashing out a rollout and calling in department heads to discuss the plan was a common approach.
Today, orchestrating change among teams that are more diverse, dispersed, and smaller creates new challenges given the complexity, magnitude, and volume of today’s change initiatives. Today, orchestrating change among teams that are more diverse, dispersed, and smaller creates new challenges given the complexity, magnitude, and volume of today’s change initiatives.
In planned change examples, where there are occasions for a considered and sometimes repeatable approach, there is an opportunity to codify a process and for all to participate and gain visibility on progress. During times of unplanned change brought about by external events, there are often very limited scenarios exercised by the management team. In extreme scenarios, teams might plan to do little more than move to a different site and open what, hopefully, is the updated runbook with instructions on what to do next.
Unfortunately, traditional tools and platforms do not enable teams to plan, execute, and learn from change events, leading to greater risk of incidents. Systematic decision making is further challenged when manual and automated activity is buried in dark matter, including spreadsheets, emails, phone calls, scripts, automated provisioning tools, and build and deployment pipelines. When disaster hits and teams are forced to comb through their data, what was previously hidden becomes all too obvious in review. To reduce the risk of IT failure and help teams succeed, they need a platform that helps plan and rehearse activities before going live, enables better communication and collaboration, supports resource management, and provides a single version of the truth.
Bringing people and automation together
The automated configuration, management, and coordination of actions, systems, applications, and processes is not new. Many tools exist that automate IT functions but fail to include human activities. An effective solution must structure both manual and automated activities into observable, repeatable processes that enable teams to tackle complex challenges. Optimizing resources is also critical as no organization executes one program at a time – hundreds, even thousands of change projects of various sizes are happening at any given time. Teams must be able to access real-time data on who is doing what and the status of all their activities across projects. In addition, manual administrative tasks must be eliminated to free up people to focus on higher value activities.
Communication and collaboration
During any event, whether planned or unplanned, teams need real-time communications showing when things have kicked off and which activities are next. The use of email and conference calls to keep teams abreast of progress and to coordinate next steps wastes time and any delays can increase the risk of an incident. Teams need to be able to communicate and collaborate with ease and have full visibility at any point in time into what has happened and what activities are next.
Visibility
Visibility is also important when we consider the prevalence of dynamic architectures, containerized workloads, and accelerated timelines. Improving visibility means keeping watch over all applications, platforms, geographies, and people. In the past, this involved manually gathering and analyzing information from many data sources—app logs, time-series data, and so on. Now, conditions are more complex. Manually assembling and analyzing data is not practical, nor plausible. Teams must have a real-time picture of every aspect of the change process as it develops, enabling them to more quickly identify and eliminate potential risks. Additionally, stakeholders need real-time status communications, playbooks that address a variety of situations, such as a major IT systems failure or data breach, and live dashboards that enable them to see high-level progress and to drill down to specific progress points at any point in time.
Audit and regulation
When things go wrong there is the inevitable post-event analysis to determine what happened and to ensure it doesn’t occur again. Usual audit activities can involve countless days of manually unearthing data from disparate sources. A system of record of everything performed is critical —what, when, and by whom. Teams need a comprehensive audit trail with visibility into all programs, ensuring regulatory and compliance requirements are met. Moreover, this data provides insights into resource utilization, goal performance, and time wastage and accuracy.
Collaborative Automation in action
Cutover’s leading cloud solution for Collaborative Automation enables enterprises to successfully manage the IT estate of applications and services for technology resilience, cloud migrations, and complex system releases by building a framework for collaboration between your teams and automation. Cutover helps teams improve processes and reduce the risk of failure. Cutover is trusted by well-known financial institutions all over the world, including the top three US banks by size and three out of the top five investment banks globally. Cutover has recently helped improve the technology resilience of a major stock exchange as well as a British multinational bank, reducing their level of risk and protecting against outages.
Facing a future of more change
The FS industry has seen sweeping technology-led changes over the past few years—and more changes are coming as AI, robotics, and blockchain evolve and digital becomes the new norm. The pace of technology transformation and big change initiatives will further accelerate. Managing these complex activities with traditional tools, such as spreadsheets, project management software, emails, and phone calls, have proven ineffective at safeguarding FS organizations from IT failures. As a result, disastrous outcomes of some recent incidents have caused governments to take notice and new regulations that force FS institutions to adopt new approaches to better manage operational risk and improve resilience are likely forthcoming.
Rather than wait for regulations to dictate how to manage IT initiatives, FS organizations can improve IT teams’ efficiency and effectiveness now with Cutover’s Collaborative Automation platform. Providing you with a centralized automated system of execution, Cutover differentiates itself with scalable and proven dynamic runbook technology that helps you transform your enterprise IT operations with a new way of working by interconnecting teams, applications, and technology. With Cutover, you can quickly access a library of comprehensive, executable, and auditable plans covering your entire IT infrastructure and their associated business owners.

.webp)

